
cekura-2
Observe and analyze your voice and chat AI agents
Someone Finally Built the QA Layer for AI Voice Agents, and It's Not the Voice Agent Companies
The Macro: The Quiet Failure Mode Nobody Talks About
Here’s the thing about AI voice agents right now. Every company from a three-person startup to a Fortune 500 is bolting one onto their customer support flow, their scheduling system, their sales pipeline. Platforms like Vapi, Bland, and Retell made it genuinely easy to build these things. Like, scary easy.
But building is not the same as knowing whether it works.
A voice agent can go sideways in production in ways that are almost invisible. It handles the test cases fine. It passes the demo. Then it gets into real calls with real customers who say unexpected things, and it starts hallucinating policy details, or dropping calls at weird moments, or just being subtly wrong about things in ways nobody catches because nobody is listening to thousands of calls manually.
This is a real problem, and it’s getting bigger. The AI SaaS segment is growing fast (multiple sources peg the AI SaaS market growing at something like 38% CAGR through the end of the decade), which means the volume of AI agents in production is going up sharply. More agents, more failure surface area.
The companies in this space are still small. Coval shows up as a direct competitor in a few tool directories. TestAI is in the mix. Elixir too. But none of these are household names yet. The observability layer for conversational AI is genuinely early, and whoever owns it when the market matures will be in a strong position. We’ve seen this pattern before in software, where the picks-and-shovels tool for a new infrastructure layer ends up being worth as much as the infrastructure itself. I’ve written about adjacent dynamics in developer tooling and the pattern keeps showing up.
Cekura is making a bet that this category gets crowded fast, which means they need to move now.
The Micro: Thirty Metrics Out of the Box and a Clever Annotation Trick
So what does Cekura actually do. It monitors and tests voice and chat AI agents, and the pitch is that you get meaningful signal without spending weeks instrumenting everything yourself.
The core product has two modes. Testing and monitoring. On the testing side, they have a library of thousands of pre-built scenarios and will run them against your agent in parallel, which means you can get real evaluation results in minutes instead of waiting for calls to trickle in. That parallel calling approach is not a small thing operationally. If you’ve ever tried to stress-test a voice agent manually you know how tedious it is.
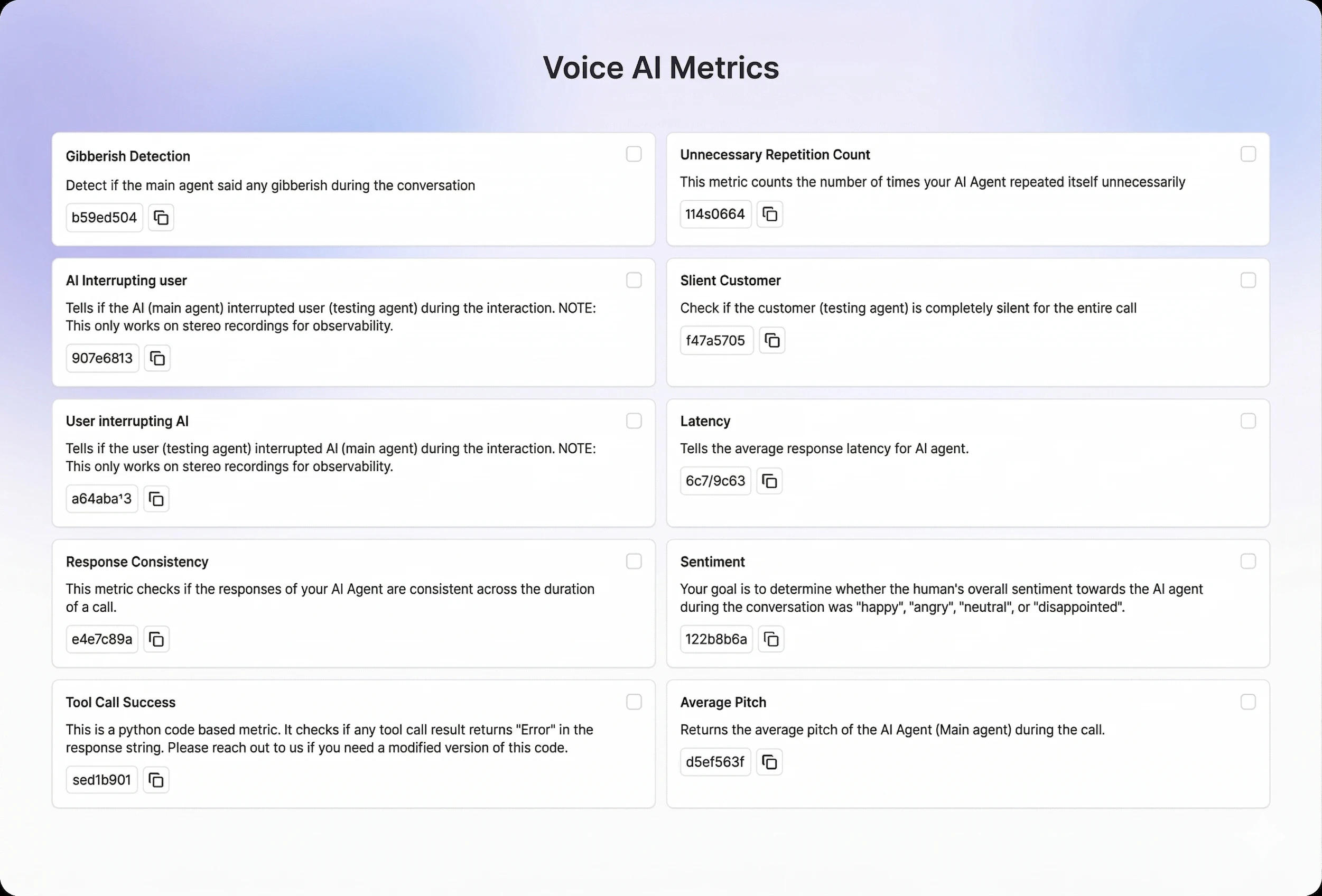
On the monitoring side, they offer 30-plus predefined metrics covering customer experience quality, conversation accuracy, and voice-specific stuff like audio quality. The dashboard is real-time and segmented, so you can actually see trends rather than just raw logs. Alerts fire when metrics shift meaningfully from historical baselines, which is smarter than just threshold alerting. You don’t want a notification every time one call goes badly. You want to know when something is systematically wrong.
The part I find most interesting is what they call Cekura Labs. You annotate around 20 conversations yourself, and the system uses that to compile a custom LLM judge calibrated to your specific quality bar. Twenty examples is a low lift. And the fact that it auto-improves over time means you’re not maintaining this thing by hand. That’s a genuinely good product decision, especially for teams without dedicated QA resources.
They integrate directly with Synthflow, Bland, Vapi, and Retell. Customers listed on the site include Five9, HighLevel, Jotform, and a few others. They’re backed by YCombinator (F24 batch), and the three co-founders are Sidhant Kabra, Shashij Gupta, and Tarush (per Sidhant’s LinkedIn). The product did well when it launched, landing near the top of Product Hunt on launch day.
The setup promise is launch in minutes, not weeks. That’s the kind of claim that’s easy to make and hard to deliver, so I’d want to test that personally before buying it fully.
The Verdict
I think this is a real problem and a real product. The question for me is whether the moat is the metrics library, the LLM judge workflow, or the integrations, because each of those is defensible in different ways and only one of them is hard to copy.
The 20-annotation-to-custom-judge pipeline is the thing I’d be watching. If that actually works as advertised, it’s a meaningful differentiator from generic observability tools. If it’s just a nice framing on something that still requires a lot of babysitting, then Cekura is competing mostly on price and distribution.
At 30 days I’d want to see retention data from teams who aren’t enterprise logos. At 60 days I’d want to know if the custom judge quality holds up across different agent types. At 90 days the real test is whether they’ve locked in any of those big platform relationships (Five9 is not a small name) at a depth that creates actual switching costs.
The developer tooling category rewards products that feel inevitable in retrospect. Cekura has the timing right. The execution details are what matters now.