
nvidia-personaplex
Natural Conversational AI With Any Role and Voice
NVIDIA Just Broke the One Rule of Full-Duplex Voice AI
The Macro: Voice AI Finally Has a Pipeline Problem Worth Solving
The boring but accurate framing for conversational AI right now is that it’s been technically impressive in demos and genuinely annoying in practice. The dominant architecture for most deployed voice AI is a cascade: audio goes into an ASR model, text hits an LLM, output gets fed to a TTS engine, and somewhere in that relay race of inference calls you lose the thing that makes human conversation feel like conversation. Backchannels. Interruptions. The “mm-hmm” that signals you’re listening without requiring a full turn transition. The whole thing ends up feeling like a very sophisticated phone tree.
Moshi, released by Kyutai in late 2024, was the first credible public demonstration that you could collapse this pipeline into a single full-duplex model. One that listens and speaks simultaneously, learning conversational behavior as a first-class concern rather than bolting it on after. That was genuinely interesting. The catch was that Moshi shipped with a fixed voice and no real role customization. You got natural-feeling conversation, but you got it on the model’s terms.
The broader open-source services market is substantial and growing fast.
Multiple research firms put it somewhere between $35B and $39B in 2025, with CAGRs in the 15–17% range through the early 2030s. The exact number varies by firm, but the direction is consistent across sources. The more specific trend inside that is increasingly loud demand from enterprises to run capable AI infrastructure they actually control, on voices and personas they define. Customer service, interactive entertainment, language learning, accessibility tooling. All of these verticals want customizable voice AI that doesn’t sound like it was recorded in a server room. That’s the gap Natural Co is stepping into.
The Micro: A 7B Model That Listens and Talks at the Same Time, With Your Voice
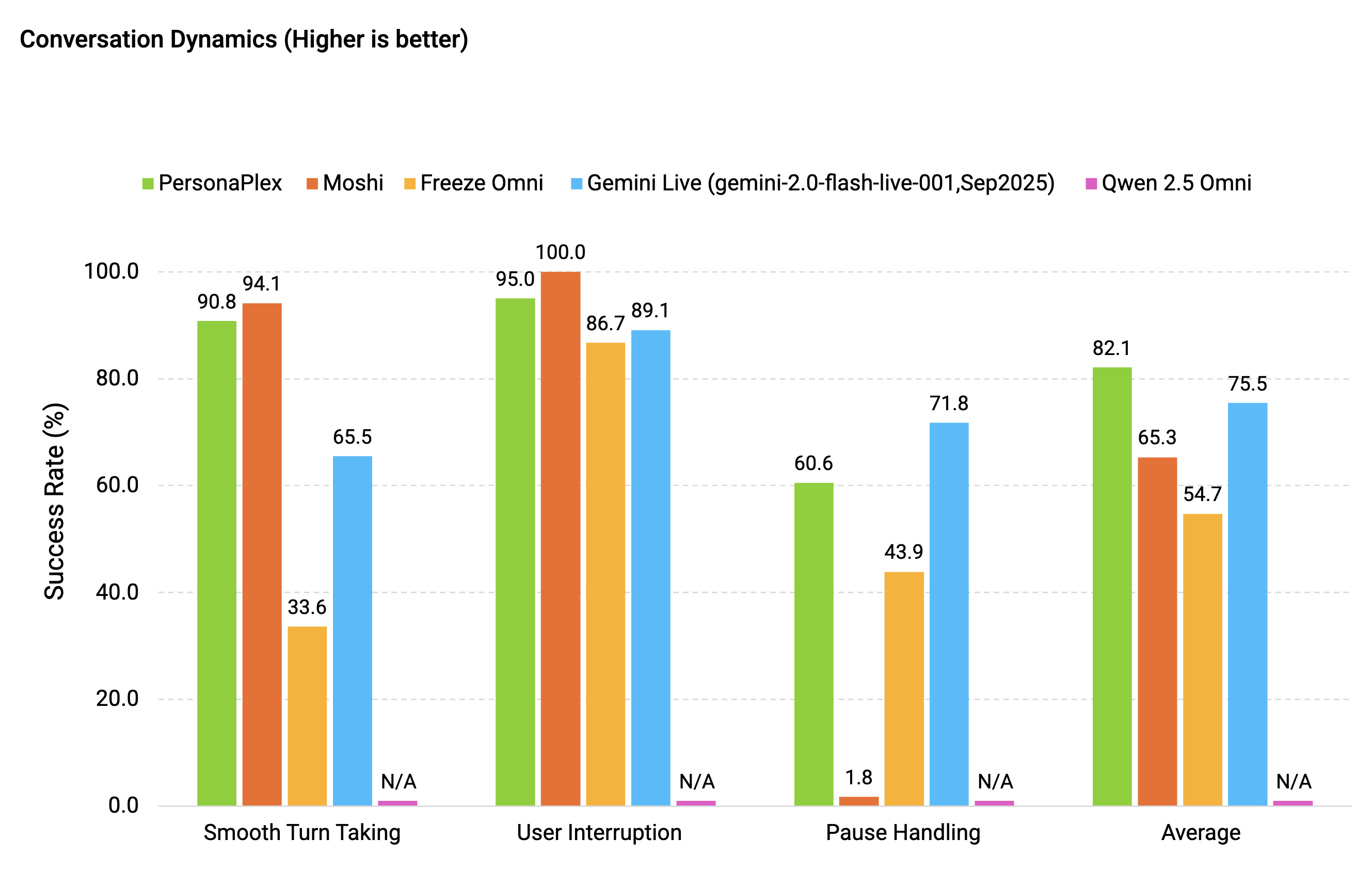
PersonaPlex-7B is a full-duplex conversational model. Weights on HuggingFace, code on GitHub, paper on NVIDIA Research, built by a team that includes Rajarshi Roy, Jonathan Raiman, Sang-gil Lee, and Bryan Catanzaro, among others. The core claim is that it solves exactly the trade-off Moshi exposed: you can have natural conversational dynamics and controllable voice and persona, not one or the other.
The mechanism for naturalness is the same fundamental architecture Moshi pioneered. The model processes audio input and generates audio output simultaneously, which means it can learn when to pause, when to interrupt, when to drop an “uh-huh” without those behaviors being explicitly scripted. NVIDIA’s benchmarking, per the product page and research materials, shows PersonaPlex outperforming existing systems on both conversational dynamics and task adherence. The specifics are in the preprint rather than summarized here. The latency figure that’s been circulating, reportedly around 0.07 seconds, is notable if it holds up under real-world conditions rather than controlled eval.
The customization layer is what makes this distinct from Moshi.
Roles are defined via text prompts: you describe the persona, “wise assistant,” “customer service agent,” fantasy character, whatever, and the model maintains it through the conversation. Voice selection appears to draw from a diverse range of options. For anyone trying to actually deploy this, that’s a meaningful practical difference.
It got solid traction on launch day. The comment count stayed thin, which tracks for a model release targeting developers over end users. Open-source, weights available, paper linked. This is a build-with-it launch, not a sign-up-for-access one.
The Verdict
PersonaPlex is a research artifact that happens to be genuinely useful, which puts it in a different category than most launches in this space. NVIDIA isn’t trying to sell you a subscription. They’re open-sourcing a 7B model that makes a specific technical argument about how full-duplex voice AI should work.
The argument is credible. The gap it’s targeting is real.
The fact that the weights are sitting on HuggingFace means developers can stress-test the latency and persona-consistency claims immediately, rather than waiting for a managed API to expose them. That’s the right way to ship something like this.
What would make this matter at 30 days: community adoption, fine-tuning experiments, and someone building something visible on top of it. What would make it stall: persona adherence degrading under anything more complex than demo-condition prompts, or the 0.07s latency figure not surviving deployment outside NVIDIA’s own infrastructure.
I’d want to know how it handles persona drift in longer conversations before fully endorsing it. And whether the voice quality holds across the full range of available voices or just the ones in the demo video.
As a bet on where conversational AI infrastructure is going, single models, real-time, controllable, the direction feels right. I think this is probably worth serious attention from anyone building in this space, and probably not yet the thing you hand directly to a non-technical stakeholder and call production-ready.
Also featured on HUGE: One CLI to Rule Them All (If You Have 44 AI Agents, Which, Look) · Cline Wants to Be the AI Agent That Actually Lives in Your Pipeline · MiniMax Wants to Make Long-Running AI Agents Economically Boring