
parsewise
Cursor for document work
Parsewise Wants to Do What Every Insurance Analyst Wishes They Could: Read All the Documents at Once
The Macro: Everyone Promised to Fix the Document Problem. Nobody Actually Did.
Here’s the thing about enterprise documents. There are so many of them. Loss reports, data room files, underwriting submissions, portfolio spreadsheets, claims histories. The actual work of most financial professionals is not analysis. It’s extraction. It’s reading the same format of PDF for the forty-seventh time that quarter and pulling out the three numbers that matter.
AI was supposed to fix this two years ago. Mostly it didn’t.
What we got instead was a generation of tools that are great at answering questions about a single document you upload. Chat with your PDF. Summarize this contract. Fine. Useful, even. But nobody in insurance or asset management is working with one document. They’re working with hundreds, sometimes thousands, and the insight only appears when you cross-reference them. That gap, between what these tools can do and what professionals actually need, is where Parsewise is planting its flag.
The broader productivity software market is genuinely enormous. According to multiple research reports, it’s on track to more than double in value over the next decade, with some estimates putting it well past $140 billion by the mid-2030s. But aggregate market size numbers are a distraction here. The real opportunity is narrower and more specific: regulated industries that have been drowning in documents for decades and are still running critical decisions on spreadsheets and gut feel.
Competitors exist. Lots of general-purpose AI tools can touch documents. What I haven’t seen many of, at least not positioned this tightly around insurance and diligence workflows, are tools built specifically for corpus-scale reasoning with traceable outputs. That specificity is either a smart wedge or a box too small to build a company in. I’m genuinely not sure which yet.
The Micro: Agents That Read the Whole Stack, Not Just the Top Sheet
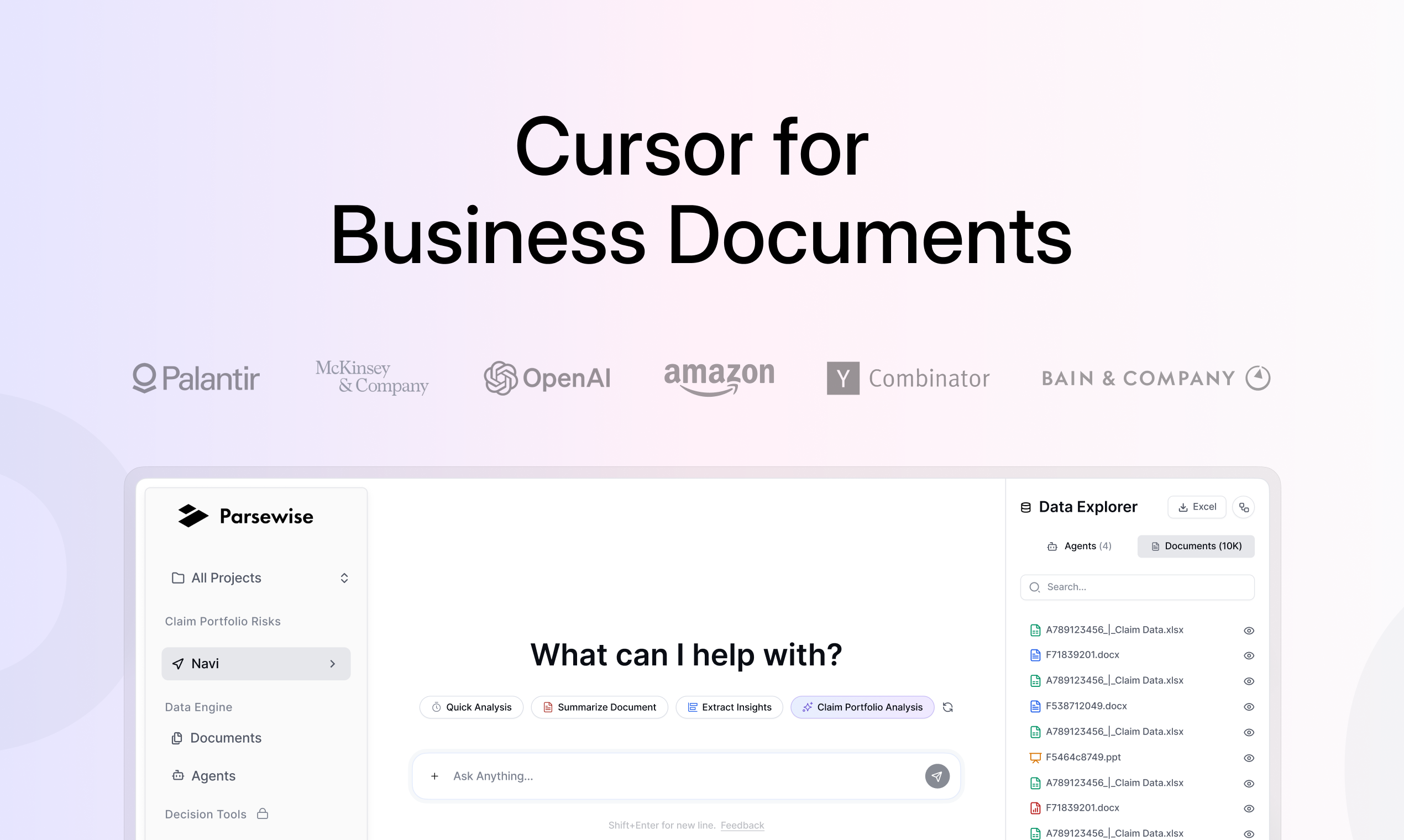
The core product idea is simpler than the marketing makes it sound, which I mean as a compliment. You configure an AI agent, point it at a corpus of documents, including PDFs, spreadsheets, emails, images, and more, and it extracts, reasons, and cross-references across the whole batch in a single run. Every output is anchored to its source document. You can see exactly where a conclusion came from.
That last part matters more than the headline feature. Black box AI in risk-sensitive industries is a non-starter. Nobody signing off on an underwriting decision wants to explain to a regulator that the answer came from a model and they’re not sure why. Source traceability is table stakes if you’re serious about selling into insurance or fund diligence, and Parsewise appears to have built it in from the start rather than bolting it on.
The no-code configuration angle is real. Users set up agents without engineering support, which removes a bottleneck that has quietly killed a lot of enterprise AI pilots before they ever got to production.
According to the company’s site, specific use cases include large loss and severity analysis, loss fund and TPA reconciliation, portfolio acquisition diligence, fund KPI validation, and company data room review. That’s a coherent cluster of workflows, not a random feature list.
The team has a credible background. Co-founder and CEO Maximilian Hofer is a YC alum, and co-founder Gergely Csegzi is reportedly ex-Palantir, which is a relevant pedigree for anyone building document intelligence infrastructure. The product got solid traction on launch day, which suggested real interest outside the usual founder networks.
I’d also point out that the “Cursor for documents” tagline is doing a lot of work. The Kimi Claw piece we ran earlier makes a similar observation about agent analogies, that they’re compelling until you actually pressure-test the workflow depth. Parsewise needs that analogy to hold under scrutiny.
The Verdict
I’ll give Parsewise this: the vertical focus is the right call. Generic document AI is crowded and commoditizing fast. Building specifically for insurance and asset management, industries with real regulatory pressure, real document volume, and real budget for tools that reduce risk, is a defensible position.
Which, look, the pitch is good. The traceability angle is genuinely differentiated. The no-code framing removes a legitimate friction point. And if the Palantir DNA translates into actual enterprise-grade reliability, this could be a serious product.
But I’d want to know, at 30 days, whether the agents actually hold up on messy real-world document sets, not clean demo data. At 60 days, whether any named insurers or fund managers are using it in production. At 90 days, whether the corpus-scale reasoning is fast and accurate enough that analysts trust it without spot-checking everything manually, because if they’re re-reading the documents anyway, the product hasn’t solved the problem.
The comparison to tools like Viktor is worth making, not because they’re the same, but because both are betting that vertical-specific AI beats general-purpose AI in high-stakes workflows. I think that bet is right. I just want to see Parsewise prove the depth is real, not just the positioning.
Also featured on HUGE: TamLabs Thinks AI Can Redesign Knowledge Work and They’re Starting with Professional Services · Dex Wants to Be the AI Coworker That Actually Lives Where You Work · Stamp Thinks Your Email Client Should Think For You